A recent article published in Science looked to the skull
shapes of early hominins, a group comprised of our now-extinct closest ancestors and ourselves, as a prediction of what sort of auditory sensitivity
they were capable of, with interesting results. The shape and size of the
auditory apparatus in animals affects the intensity with which each frequency
register is perceived. In the study, the inner ears of early hominins,
chimpanzees and modern humans were scrutinized, and the modeled ear parts of
each were used to make predictions regarding the frequencies that were more
easily heard, and the results were plotted as shown below.
Fig. 1: Sensitivity to sound over a range of frequencies (article in discussion)
In the figure, the y-axis corresponds to the log of the ratio of sound power to reach the cochlea, Pcochlea, versus that of the sound source, Po, as a measure of the perceived sound intensity. The researchers
conducting the study were able to show that the early hominins had a higher
sensitivity to sound at around 3kHz than both chimpanzees and modern humans and
generally higher sensitivity to lower frequency sounds as well, showing a
decrease in sensitivity at higher frequencies that is more similar in trend to
the hearing curve of chimpanzees than it is to humans. Modern humans, in
contrast to the others, have a similar sensitivity curve at lower frequencies
but extend hearing to higher frequency sound, dropping off near 4kHz
frequency. In analyzing this finding, the researchers came to the conclusion
that the adaption to a wider frequency range of hearing in modern humans was
imperative for the development of consonants in human language. The researchers
considered that the phonemes t, k, f and s in particular are associated with
higher frequency sound and that the ability to perceive sound over a wide range of
frequencies makes these sounds more distinct from each other. Since early hominins
were incapable of perceiving the upper frequency range that modern humans can,
the researchers postulate that communication between the early hominins would
have been vowel-intensive. They make a point, however, of stating that this
finding does not confirm any information about the extent to which early hominin
language was used or developed; early hominins may have used a “low-fidelity
social transmission” form of communication similar to that of modern chimpanzees.
Nevertheless, the skulls of these early hominins have given us another insight
into what life was like for some of our earliest ancestors.
The complete article on the differences in sound perception described above is available here. While the article is heavy on jargon, the results and discussion sections can be understood without fully understanding the early talk of ear anatomical differences.
Also, please let me know your thoughts on this trial article in the comments. I am trying something new with the posts here, providing brief summaries of emerging science rather than explanatory articles of everyday phenomena. Feedback helps me decide what content I post. Thanks!
A recent survey by the Pew Research Center found that
Americans are more likely to answer correctly questions related to basic science
concepts than to scientific understanding [1]. Among the bank of questions, ones such
as which layer of the earth is hottest and whether uranium is used in nuclear
energy were answered correctly more often than ones such as whether the
amplitude of sound waves causes its loudness. The question answered incorrectly
most often was whether water at higher altitudes boils at lower temperatures with
only 34% of respondents knowing that, indeed, it does.
Fig. 1: Results of Pew Research Center survey (Pew Research Center, same as reference 1)
Public scientific literacy is an important goal to work
towards for developed countries. As Cary Funk and Sara Kehaulani Goo of the Pew
Research Center posit, the ability to understand scientific concepts is crucial
to people being well enough informed about current issues such as GMOs and the
energy crisis to make educated decisions in the polls. Scientific literacy also
makes daily life easier by finding more efficient solutions to everyday problems.
As a small step towards improving scientific understanding,
let us discuss why it is easier to boil water at higher altitudes.
Liquid water and water vapor exist in a sort of equilibrium.
There are a number of factors that can shift this equilibrium, but one we
interact with daily is temperature. Say you spill a glass of water. Of course,
a large spill would require immediate attention, but if only a thimbleful of
water was spilt, some would be inclined to let it evaporate. Evaporation involves
two main processes at play. First, the water is receiving kinetic energy from
its surroundings in the form of heat energy. Second, the water is in higher
concentration in the spill than in the spill’s surroundings and therefore a
concentration gradient is formed at the water’s surface.
So what has this all got to do with boiling water? Well, water
boils when transforming into a gas. Therefore, boiling water is a phase
transition described by the equilibrium between liquid water and water vapor. Besides
temperature, pressure also affect liquid-gas equilibrium as described by the
ideal gas equation,
1.PV=nRT (P is pressure, V is
volume, n is number of molecules in moles, R is the gas
constant, T is
temperature)
LeChatelier’s principle states that a system in equilibrium
will move away from an induced change. In the case of an increase in pressure, we
can see that if n and T remain the same then the ideal gas law describes a shift
to decrease V, volume. On the other hand, a decrease in pressure should cause a
shift towards a higher V. This means that at lower pressures, water prefers to
exist in a gaseous state and the equilibrium shift will cause the water to
boil. This is the foundational concept of rotary evaporators, which use the
concept of reduced-pressure boiling to remove solvents.
Fig. 2: Deriving atmospheric pressure in atm's (Pearson)
Now all that is left is to link pressure to altitude, which
isn’t too hard. By definition, atmospheric pressure is defined as the weight of
the atmosphere over an area at sea level [2]. For example, one inch of land at
sea level partitions a pillar of atmosphere weighing 14.7 lbs, so atmospheric
pressure in PSI is 14.7 lbs/in2. A logical extension of this concept
would tell us that at any altitude greater than sea level, the pillar of air
would be shorter and would consequently weigh less. This is the missing link we
were searching for between pressure and altitude. Putting all of the above information
together, we see that a decrease in pressure causes liquid water to favor boiling
and that an increase in altitude causes atmospheric pressure to decrease. Therefore,
water boils easier at higher altitudes.
Scaling the results of the survey to education levels, the
Pew Research Center also found a correlation between higher education and
scientific knowledge. But this is not a given. Even as college students, we must
all work towards insuring that we are among the scientifically literate ready to
contribute educated opinions to today's social debates.
Is there really a founding for believing in herbal medicine?
This seems to be a question many Americans are asking in a time when the
concept of “human is better” is waning in favor of a return to an attitude that
acknowledges we have a lot to learn from nature. Much of herbal medicine may
seem like hocus-pocus, but scientists are not as against herbalism as some
would think.
A first thought when someone mentions herbal medicine might
be something along the lines of dried seahorse and mummified gecko. This is especially
true for Americans where there is a high Chinese cultural medicine presence and
where such practices are often caricaturized by the media. However, not all
herbal medicine is so strange. Some common examples of herbal medicine practice
could be honey-ginger tea for a sore throat and aloe (Aloe vera) for sunburns, both of
which can be commonly bought in major store chains. As it turns out, much of
the world uses some form of herbalism [1]. This shouldn’t come as a surprise. It is against human nature to accept illness as it comes, so wherever
there are people there is likely to be medicine as well. But living in the time we do, both traditional herbal medicines and contemporary scientifically
produced medicines are readily available. So which should we choose?
Fig. 1: Herbal medicine utilization by country (ClubNatu, same as source 1)
Herbal medicine is steeped in traditional medicine practices that developed before the scientific method and its instruments were available. Yet even so, many herbal remedies have come about through a rather logical process. Take even a fictitious, highly religious pre-scientific society where medicines are attributed to gods. If a medicine doesn’t heal its patient, then the instinct is to throw it out primarily because it’s useless and perhaps also because it makes the gods look bad. Our ancestors were smart enough to develop a working knowledge of herbs through thousands of years of trial and error, a highly valued logical test still used today in medicine development.
The argument some give in favor of a return to herbal medicine
is that it’s more “natural” than modern synthetic drugs. This is not a
well-based argument from a scientific perspective. Instead, we should consider factors
such as effectiveness, side-effects, general safety of the herbs and the ecological
impacts of its widespread prescription, each of which must be individually assessed per herb. The effectiveness of herbal remedies is
a subject of increasing research attention as many have proven to possess clinical
efficacy. Aspirin, for example, emerged from a more mild treatment of salicylic acid, a chemical
found to exist in the bark of the white willow (Salix alba) tree used in traditional medicine. It has recently become a growing practice to scientifically
test a wide number of natural products and traditional remedies as a high-throughput system for scouting out
potential new treatments. Some herbal remedies have also been found to offer their
effects with less side effects than modern medicine [2]. This could be due to a
plethora of possible reasons including active dosage or the presence of other
compounds to neutralize negative effects.
Fig. 2: Most popular natural products (including herbs) in the United States (NCCIH)
So where do herbal medicines fall short? All medicines have
their associated risks, but a lack of herbal toxicity knowledge and of prescription guideline enforcement brings
into question the safety of some herbal medicines [3]. The ecological effects of manufacturing
herbal medicines must be considered as well. Paclitaxel, a drug with anti-tumor
properties listed on the World Health Organization’s List of Essential Medicines,
is a natural product from the bark of the Pacific Yew (Taxus brevifolia) tree [4]. However,
wild-crafting this compound would devastate the tree population. Thus there is an inherent economic limitation on herbal paclitaxel, and so the synthetic
generation of this natural compound is now the main route of production.
Herbal medicine is a topic that has been making a
comeback under the realization that we have much more to discover about our
medical pasts through a scientific approach. Personally, I am inclined to believe
this is a step in the right direction since it is never bad to know more about plants that could potentially save our health. After all, it takes just one
paclitaxel to make the search worth it. Social opinions on herbalism as a form
of alternative medicine are shifting towards the positive, and as
scientifically educated individuals we should keep ourselves updated on this
movement.
If I gave you a sheet of paper and asked you to draw me a nickel, you’d probably draw me a
circle roughly an inch in diameter, maybe labeled with a "5₵". If I asked you to draw me a mite, the smart
alecks out there would probably dot the piece of paper and give it back. If I asked
for a realistic drawing of an atom, the same group would likely hand me back the blank
page. This sort of answer is likely meant to be taken as a joke, but it also provides us with an insight into the limitations of human visual resolution.
Human eyes are anything but perfect, and some are less perfect
than others. And as the silly drawings of the mite and the atom suggest, the smaller the object the harder it is for the human eye to resolve. By the
international standard of measuring human visual resolution, good vision is
defined as 20/20 (feet system) or 6/6 (meter system), meaning that someone with
20/20 vision can resolve what a person should be able to see (by designation) 20
ft away at the intended distance [1]. Someone with 20/40 vision sees at 20 ft
what someone with 20/20 vision can see at 40 ft away, and someone with 20/10
vision sees at 20 ft what someone with 20/20 vision can see at 10 ft away. As objects
get smaller, they seem to us as tending to a point. This occurrence is often referenced in physics where a source with radius r a distance d away from a sensor where d>>r
(d is much greater than r) can be approximated as a point source.
But how exactly do we characterize this phenomenon, and at what
distance does leaning forward while squinting intently seem… pointless? Let's take a look
at the diagram below:
Fig. 1: A Spherical Object Viewed at Different Distances (Orig.)
On the left side there
is a spherical object of radius r1 being observed by the first eye
at a distance d1 so that the object fills the observer’s field of
view (denoted by the first set of dashed lines). The circle surrounding the object with radius r2 represents
the same observer’s field of view at a distance d2 where d2>d1.
The corresponding angles are drawn in and labeled as θ1 and θ2.
From this diagram, we can obtain the equations
1.r1=d1tan
θ1
2.r1=d2tan
θ2
3.r2=d2tan
θ1
Dividing equation 1 by equation 3, we receive the statement
4.r1/r2=
d1/d2
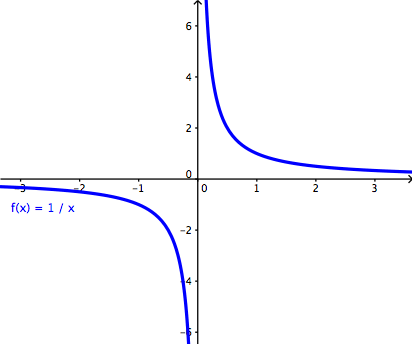
This equation tells us that as d2 increases, the
ratio of the original full-view object radius to the radius of the field of
view at d2 decreases as d1/d2=k/d2 α
1/x (k is used to show that d1 is a constant). The graph of 1/x is shown below:
Where the x axis represents an increasing distance d2
and the y axis represents the ratio r1/r2. This finding
seems to agree with our experiences, doesn’t it? Namely, as we walk further away
from an object it seems to decrease in size relative to our entire field of
view, the size difference becoming less noticeable as distance increases
further. If we were to walk far enough away, then the object would appear as if
it were a point in our vision.
So we now know how to describe the way objects seem to
decrease in size at far distances, but at what distance does any sort of difference
in the object not matter? That is, when does the object become a point? Based on the human vision resolution assessment described earlier, we know that at 6m, or 20ft, the idealized human should be
able to resolve a standardized interval of one arc minute, or
1/60° [2]. From rearranging equation 3, we receive the form
5.d2=r1/tan
θ2
Making the substitution of the maximum
resolution for a 20/20 person’s vision, 1/60°, for θ2, we produce the
equation
6.d2=3,438r1
This equation says that an object with a radius r1 can be
seen from a distance a factor of 3,438 times its radius before a person with
good vision can no longer sense its character beyond that of a point. This is
like trying to see the face of a nickel from 146 meters away. While seemingly too far a distance to be visible, if we check equation 6 by substituting in the resolution corresponding to an arc minute at 6m, which is 1.75mm [3] (this can be checked with equation 1), then the distance returned is indeed
6m. With this information in mind, the next time you look up
into the night sky I challenge you to think about just how big a star is compared to the
twinkling dots you see above. Suddenly, it won’t seem so crazy to say we all live on
the head of a pin.
Thank you guys for reading this post, and be sure to look
out for more to come. If you want to be updated whenever I make a new post, sign
up for email notifications on the right side column of the blog so you can have
new posts sent directly to your email. Alternatively, if you send me a message on Google+ I'll add you to be notified when I post new content. If you have any suggested topics for
future posts or you liked this post, let me know in the comments because I’d love
to hear your thoughts. Thanks!
For my birthday a while back, a friend of mine gave me food
coloring, a box of borax and spools of thread. I asked what they were for, and
she said crystals.
Fig. 1: Borax crystal growing birthday gift (orig.)
Of course! I hadn’t ever seen people grow borax crystals
before, only sugar or salt, so I looked up a tutorial on YouTube. The procedure
was pretty standard: heat water up to near boiling, dissolve the borax, insert
a pipe cleaner or thread and wait overnight for the solution to cool down and
precipitate out crystals. But while the procedure is simple, the science behind
nucleation is more complicated and pretty interesting.
In order for a crystal to form in solution, molecules of a
substance must conglomerate to an adequate size to encourage the spontaneous coordination
of more molecules. A cluster of this adequate size is called a "nucleus," and
the process of its formation is called "nucleation." Clusters that are not large enough to be nuclei are called "embryos." The nucleation process can
be described in terms of Gibbs free energy, which accounts for both enthalpy,
related to the nucleus’ internal energy, and entropy. Gibbs free
energy is given by the equation
1.ΔG=ΔH-TΔS (H is enthalpy, T
is temperature in Kelvins and S is entropy)
For a newborn crystal born homogenously (meaning suspended
in a medium without contact with other surfaces), there are two main energy changes
that are occurring. The first is a lowering of molecular energy due to the
formation of attractions between coordinating substance molecules for reasons described
in Why Cold Drinks "Sweat". This change in energy can be describe by the equation
2.ΔG=VΔGv (V is
volume, ΔGv is the change in internal energy per unit volume)
To find ΔGv, we will assume that the
crystal-solution system is cooled to slightly below the substance's melting point, Tm.
At this small undercooling, ΔH and ΔS can be approximated as temperature
independent [1]. But first, at Tm the difference in free energy ΔG
between a substance’s solid and liquid forms is 0. Therefore,
3.ΔGm=ΔH-TmΔS=0
4.ΔSm= ΔH/Tm
Now, assuming that ΔH and ΔS are temperature independent, we
can use the same expression for entropy as used at Tm to find the
value of ΔGv. While we’re at it, let’s assume the crystal nucleus is
spherical for simplicity’s sake. The following are therefore true:
5.ΔGv=ΔHfv-TΔS=
ΔHfv-T(ΔHfv/Tm)= ΔHfv(Tm-T)/
Tm= ΔHfvΔT/Tm (from equations 1 and 4)
6.ΔG=VΔGv=4/3πr3(ΔHfvΔT/Tm)
(from equations 2 and 5, Vsphere=4/3πr3)
The second energy change occurring is an increase in a
newborn crystal’s energy because the surface of the crystal is disrupting
bonding in the liquid medium around it. This change can be described as
7.ΔG=Aγs=4πr2γs
(A is the nucleus’ surface area, γs is the surface free energy
value
characteristic of the medium-solid interface)
This expression is just the disruption free energy per unit
area multiplied by the surface area of a sphere. Together, these two energy
changes dictate nucleation. Putting the two expressions together, we get
8.ΔGhom=VΔGv+Aγs=
4/3πr3ΔHfvΔT/Tm+4πr2γs (ΔGhom indicates that this equation is for
homogenous nucleation)
This equation is very useful and can be used to describe
nucleation events from borax crystals precipitating to homogenous cloud
formation. To tease a little more information out of equation 8, let’s see how ΔGhom
changes in response to a substance clump slowly growing in radius. This rate
of change corresponds to the derivative of ΔGhom with respect to
radius r [2];
9.d(ΔGhom)/dr=4πr2ΔGv+8πrγs
The point where ΔGhom no longer changes with r
corresponds to the peak on the following graph of equation 8 and its component
parts, equations 2 and 7.
Equation 2 is shown as a decreasing curve because ΔHf is
negative for crystallization. This makes sense because as a material crystallizes,
energy is lost to its surroundings, so ΔHf must flow out of the
system. To find the critical nucleation radius,
10.d(ΔGhom)/dr=4πr2ΔGv+8πrγs=0
(from equation 9)
11.r*=2γs/ΔGv
Plugging the critical radius into
equation 8 and extracting the negative from ΔHf to avoid confusion, we get
This expression describes the
magnitude of the energy change needed to get a molecular cluster up to the size
of the critical radius r*, a sort of activation energy [3].
However, homogenous nucleation is relatively difficult compared
to heterogenous nucleation, as I’m sure you’ve probably heard. Heterogenous
nucleation occurs when a nucleus forms on a surface, such as a dust particle
for clouds or thread for nucleating borax crystals. Because of the complexity of
finding heterogenous nucleation equations due to complex volume and surface area
terms as well as extra surface energy considerations, I will not be posting these
calculations. The calculations can be found in reference 3, but the summarized result is
that the critical radius in heterogenous nucleation remains the same as with
homogenous nucleation while the nucleation free energy lowers and makes the
nucleation process more accessible. This is why minimizing dust or rough
surfaces is important for growing larger crystals rather than clusters of small
ones.
What has been described above is just a small bit of the complexity
of crystal growing. Knowledge of nucleation rates and crystal growth is widely
used in processes such as tuning metals to have properties fit for specific
purposes or growing single-crystal silicon for computer processors, and I’m
sure this information will come up again on later posts. But mild difficulty of
math aside, it’s cool stuff, huh? As a treat for reading through this post, watch this fun Minute Earth video on the homogenous nucleation of clouds and see if you recognize some of the concepts we discussed.
I’m planning on growing some borax crystals soon, and when I
do I’ll likely write an experiment post about it so be sure to come back and
check that out. I’ve already had my first few days of classes and so far it
seems that I will be able to continue posting once a week, likely on Sunday or Monday.
As always, thanks for reading and I’ll be posting new stuff soon!
Colors are
a ubiquitous fact of human life. Imagine a world without colors; all of the
great masterpieces would be painted in gray scale, that potato could be purple
or brown and there would be no more blue skies. Experientially, we are highly
familiar with the concept of colors, but I would say it isn’t common to
understand the more technical side of the world of colors. Let’s explore this
more analytical side and it’s applications as we try to answer a question most of
us have probably had: why are there multiple sets of primary colors?
At the
most basic, colors are categories of light within the visible spectrum that can
be described as having either different wavelengths or frequencies since the
two variables are directly correlated by the equation
1. c=λv (c is the speed of light, λ is wavelength and v is frequency)
The visible spectrum is comprised of the rainbow colors
describe by the acronym ROYGBIV (red, orange, yellow, green, blue, indigo and violet). Fig. 1: Visible spectrum for humans (Arstechnica)
White is the presence of all wavelengths while black is the absence of
light. Technically, there is no physical meaning associated with colors since the color spectrum is defined based on
human capacity to perceive and differentiate different colors. That is to say,
the visible spectrum and colors would be defined very differently had we been
insects able to see UV light [1]. So keep in mind that all of this talk of analyzing
colors is human-specific and don’t go off trying to explain it to your dog.
The human
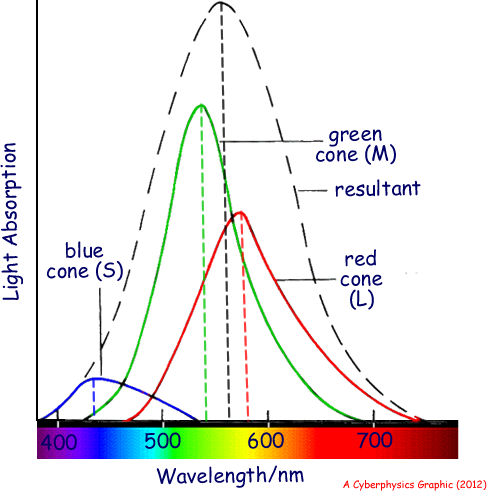
eye consists of rods, which perceive low intensity light, and cones, which
perceive colors and high intensity light [2]. There are three types of cones,
dubbed L, M and S, that respond to different wavelengths of light. The peak sensitivities
for these three cone types are 580nm (red), 540nm (green) and 440nm (blue)
respectively, adding to a maximum sensitivity at 560nm (in the yellow-green region
of the spectrum) [3].
Fig. 1: L, M and S cone response curves and response sum (Cyberphysics)
This should start to sound familiar for those of you who are familiar with the concept of primary light colors or who have ever squinted really hard
at a television screen. Aside from these three colors, other colors are
perceived by simultaneous stimulation of multiple cone types. The color mixing
ratios of red, blue and green light to perceive every color was actually
indexed in 1931, creating the RGB CIE 1931 system [4]. The impact of breaking
each color into three values of red, blue and green, called the RGB tristimulus
values, is that each color can now be defined in three-dimensional space as a
combination of three basis vectors representing red, blue and green relative
intensity values. The mathematical derivation can be found in reference 4, but
the result is the chromaticity diagram familiar to aficionados of tech wanting
to know what range of human-perceivable colors their devices are capable of
displaying. Look along the edge of the chromaticity diagram and you should find
a color wheel for light.
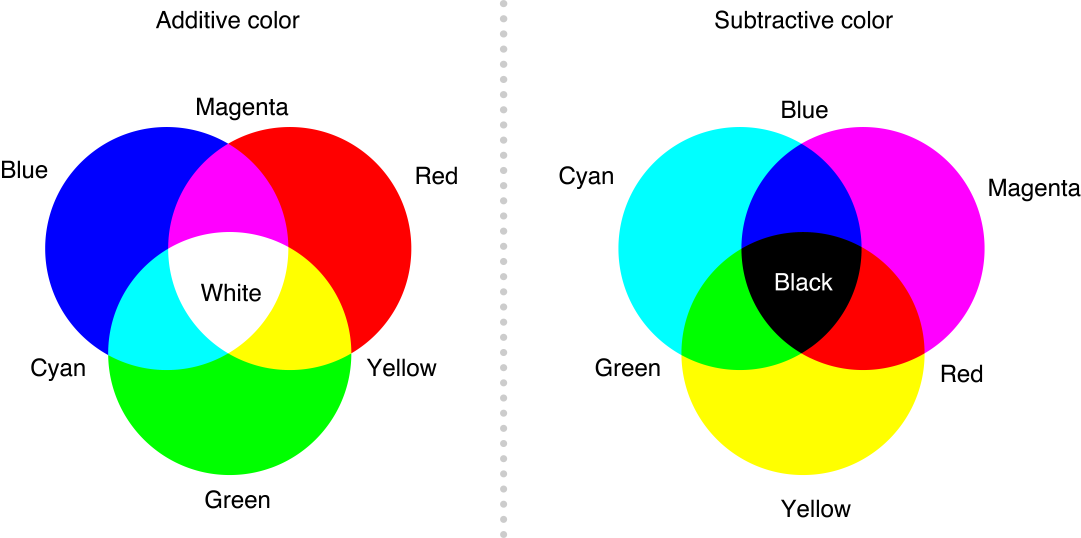
So far we have one set of primary colors consisting of red, blue and green that has widespread applications in electronic
devices since many of these generate colors for humans to perceive when watching
movies or reading billboards and such. But this set of primaries and its corresponding
wheel only apply to the production of light by adding ranges of wavelengths
together. This is called additive color. When light is absorbed by colored materials via
quantum effects, as has been described in Thoughts in Black Ink, the color perceived is the light range that has not been absorbed. To describe the phenomenon of light
absorption to generate a reflected color, the painter’s wheel was invented by
Isaac Newton in 1666 [5] with the familiar primaries of red, blue and yellow. What
this wheel describes is how subtracting light with certain ranges of wavelengths
stacks to reflect light of a certain color when starting with ambient pan-frequency
white light. However, this is not strictly subtractive color because the
painter’s wheel adds to brown, not black as anyone who has tried to make black paint
from the primaries in art class knows. The subtractive color wheel is defined
with yellow, magenta and cyan as primaries and should be familiar as the
different ink cartridges you probably put in your printer so that your computer
can print black in theory (but black ink is cheaper).
Why these three colors? It
turns out that if you take the three primary colors of light, red, blue and
green, and combine them two at a time, you get cyan, magenta and yellow [6]. And
since the color of a surface is what the surface doesn’t absorb, each
subtractive primary color cancels out one of the additive primary colors until
no light is left. And there you have it, the three most common primary color
sets.
This post was made in response to a comment by my friend Lilia back on the article How Soap Helps Us Clean. I haven’t address the comment until now because I knew
there would be a biological component to this explanation and cellular biology
is not my strong suit, hence the brevity with which I describe the rods and
cones of the eye. But if you guys have anything you would like to hear about, feel
free to leave suggestions in the comments below and I will do my best to write a post for you. Thanks!
With a horrible heat wave hitting the Philadelphia area,
it’s good to think cool thoughts. Already feeling the heat last night, I left a
coconut water in the freezer with the intent to drink it but forgot and so took
it to work this morning frozen solid. I figured since it’s so hot outside and
the metal can is a good conductor, it’d probably melt pretty quickly. And while
the ice in immediate contact did melt, the inside remained frozen and I had to
cut the top open with scissors to eat it. Before I figured this out, the can
had already shed a puddle at my desk. Have you ever wondered why it is that
cold things "sweat."
Fig. 1: My favorite coconut juice brand, Foco (pinstopin.com)
Most of us are familiar with the concept of condensation,
having learned about the water cycle in elementary school. We are commonly
taught in elementary that water exists as vapor at hot temperatures, condenses
to liquid as the temperature drops and eventually expands (not condenses, as
ice has a lower density than water due to hydrogen bonding) into ice as the
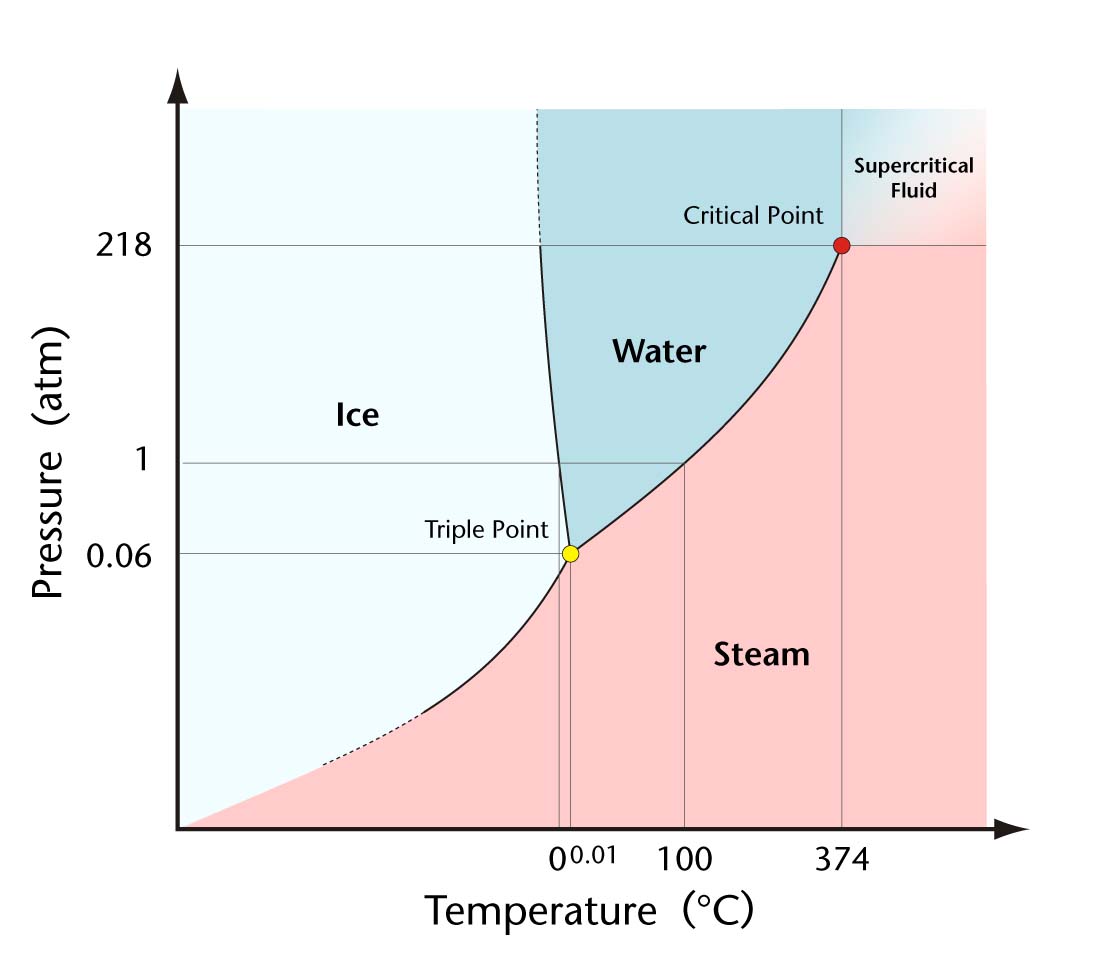
temperature drops further. In high school, we learn about the ideal gas law and
how pressure also affects phase transitions, yielding the phase diagram.
So from this standpoint, we are all familiar with why cold
things "sweat." What else is there to it? While the basic principles stand,
there are some other viewpoints from which we can view this phenomenon.
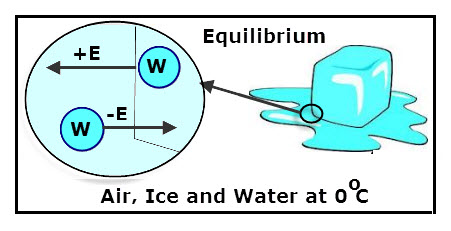
Phase transitions can be viewed as being an equilibrium
process, as is demonstrated by the fact that an ice and water mix maintains a
0°C temperature. In such a mix, the ice melting and the water freezing are
competing processes that are controlled by environmental factors; if you cool
the mix the ice expands, but if heated the ice melts. Additionally, the entire
mix must either become ice or water only before the temperature can deviate
significantly from the equilibrium temperature of 0°C. What’s cool about this
process is that if you track the energy entering the ice and water mix, say a
glass of iced coconut water (let's treat this as an ideal glass of pure iced water), we can predict the corresponding
phase transitions based on molecular kinetics.
When bonds are formed, whether strong or weak, we know that
energy is released as heat. The reverse is true as well, breaking bonds
requiring energy. The direction of bond energy transfer can be simplistically remembered
taking into account the conservation of energy in a two molecule one-dimensional
collision. Say two water molecules are moving towards each other and stick together upon impact. Where did the kinetic energy go? Ignoring molecular vibrations, the energy
had to have been released as work, or heat. In order to separate the water
molecules, we need to get them to move apart, a.k.a. add work, or heat, to yield
kinetic energy. In our glass of iced water, this sort of energy transfer is
happening extremely fast and on a large scale, one that can be described by Le
Chatelier’s principle since the ice and water form an equilibrium.
Now let’s put the iced water outside on a hot summer Philadelphia
day. From experience, we know that the ice will melt and the water will become unappealingly warm. If we track the direction of energy transfer, the higher
energy hot air must be donating energy to the lower energy iced water simply because
this is the default direction of energy transfer in our universe according to
the Second Law of Thermodynamics. The added energy must translate into kinetic
energy as temperature is positively correlated to molecular kinetic energy. From
our two water molecule system we know that a decrease in water molecule association
is predicted, favoring water over ice and vapor over water. This manifests as the
ice melting and the water warming and eventually evaporating.
What has been so far described, however, is only focused on
the iced water itself. Let’s change our basis to focus on the hot air along the
iced water glass instead (assume the water glass does not hamper kinetic energy
exchange between air and iced water). Hot air carries a lot of water since at
higher temperatures water enters the vapor phase preferentially according to Le
Chatelier’s principle. From the viewpoint of the air, the cold iced water is
pulling kinetic energy from it, accordingly cooling the air within a certain
range of the glass. Plugging this information back into our two molecule
system, the energy must be afforded by reducing the molecular kinetic energy of
the air, increasing the probability of water existing in associated groups, i.e.
water. And this is why a cold drink sweats in the summer.
Since school is starting up again, I will not be able to
post as frequently as I have been during the summer. I will try to post at
least once a week, and will probably be doing so during the weekend since this
is when time is most available. Please have patience with me on this, and as
always thanks for reading!